
12月4日-5日,由清華大學人工智能國際治理研究院主辦的2021人工智能合作與治理國際論壇在清華大學舉行。在以“人工智能技術前沿與治理”為主題的論壇中,中國工程院院士、北京大學信息科學技術學院院長、鵬城實驗室主任高文分享了人工智能2.0的戰略、戰術和安全問題。
高文介紹,中國人工智能發展規劃是從2015年7月份開始,2017年7月發布的《中國人工智能發展規劃》就是人工智能2.0正式的說法,提出2020年達到與世界先進水平同步,2025年部分領先,2030年總體領先。
他在演講中分享到,通過和歐洲、美國等國家在人才數量、研究水平、開發能力、應用場景、數據、硬件等方面的比較分析,中國人工智能發展的水平,存在“四長四短”。即在人工智能發展政策支持、海量數據資源、具備豐富的應用場景,以及青年人才數量和成長速度等方面具有優勢;在人工智能的基礎理論和算法、高端芯片和關鍵器件、開源開放平臺,以及高水平人才數量等方面則存在短板。
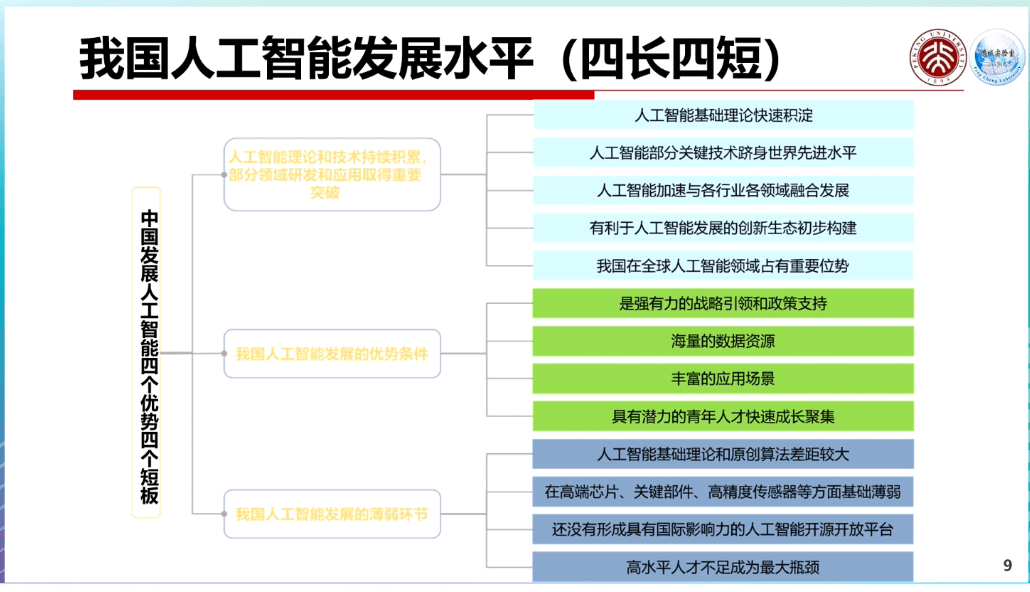
“在短的方面傾注一些資源,盡快補齊短板,使得長板更長,短板不短,發展人工智能是這樣的戰略。”高文稱。
具體戰術應該怎么做?高文表示,人工智能2.0需要重點考慮兩個方面。一是做可解釋的機器學習+推理,在小數據、可解釋模型的研究主線上,解決人工智能的問題。第二個技術路線是靠深度神經網絡,利用仿生系統+AI大算力解決問題。
高文認為,第二條路線會是人工智能現階段發展的主要推動方式,而靠大數據、大算力來做人工智能,關鍵需要有基礎設施平臺,需要有非常大的算力。
據了解,高文在2018年主導成立的鵬城實驗室在去年就推出了算力高達1000P FLOPS(每秒計算速度達10的18次方)的鵬城云腦2,做到節點之間延遲低、帶寬非常寬,從而使得機器訓練的時候,大數據很容易傳輸,效率可以發揮到極致。鵬城云腦2在連續三屆世界超算打榜中吞吐性能方面絕對領先,在世界人工智能算力500排行中也連續兩次獲得第一。
高文介紹稱,用這臺機器已經訓練了若干個大模型,比如基于自然語言處理的大模型鵬程·盤古,基于計算機視覺、跨模態的大模型鵬程·大圣,基于多對多模式的模型鵬程·通言,以及面向生物制藥、基因制藥的大模型鵬程·神農等。他表示,鵬程系列模型基本都支持開源開放,通過啟智開源開放平臺提供開源開放的程序,可以下載進行使用。
但由此也會帶來新的問題。“如果基于類腦和大數據、大算力的技術路線,很顯然有一個坎兒必須要邁過去,就是數據安全和隱私問題。”高文表示,這需要從兩個層面考慮,數據和隱私安全問題、人工智能倫理問題。
對于數據隱私安全問題,高文認為,人工智能應用離不開數據,在隱私保護和數據挖掘之間,需要找到比較好的平衡點。
這個平衡點在哪里?高文分享了一種隱私和數據安全保護的手段——把數據模型和應用分成三層,每層用接口隔離開(數據到模型之間通過數據程序接口隔離,模型到應用通過應用程序接口隔離),這樣就有可能去規范,對數據進行保護。
比如在數據和模型之間,鵬城實驗室設計的防水堡技術就可以實現對數據只分享價值,而不分享數據的可信計算環境,做到數據可用不可見,使得數據擁有方或數據本身得到很好的保護。
關于倫理問題,高文介紹了其牽頭的研發成果,認為強人工智能安全風險的來源主要有三個:一是模型的不可解釋性,二是算法和硬件的不可靠性,三是自主意識的不可控性。強人工智能進化到一定程度就有自主意識,這些可能是不可控的,也會帶來一些安全風險。
高文就此也提出了預防和解決的辦法。一是要完善理論基礎驗證,實現模型可解釋性,可解釋了就知道哪里有風險,怎么樣預防;其次要對人工智能底層價值取向要嚴格進行控制,預防人為造成的人工智能安全問題,對人工智能進行動機選擇,為人工智能獲取人類價值觀提供一些支撐。
他還表示,對于人工智能倫理問題的探索才剛剛起步,只有廣泛的國際合作才可能更好的應對風險。同時,教育也是重要環節,培養對這個領域有更多見解的人才,才有可能把這些問題解決好。來源:搜狐科技
 金大立免費服務熱線
金大立免費服務熱線 地址:成都彭州市工業開發區天彭鎮旌旗西路419號
地址:成都彭州市工業開發區天彭鎮旌旗西路419號二維碼
